100 USDT


Определение рейтинга моделей ИИ в генерации кода Solidity
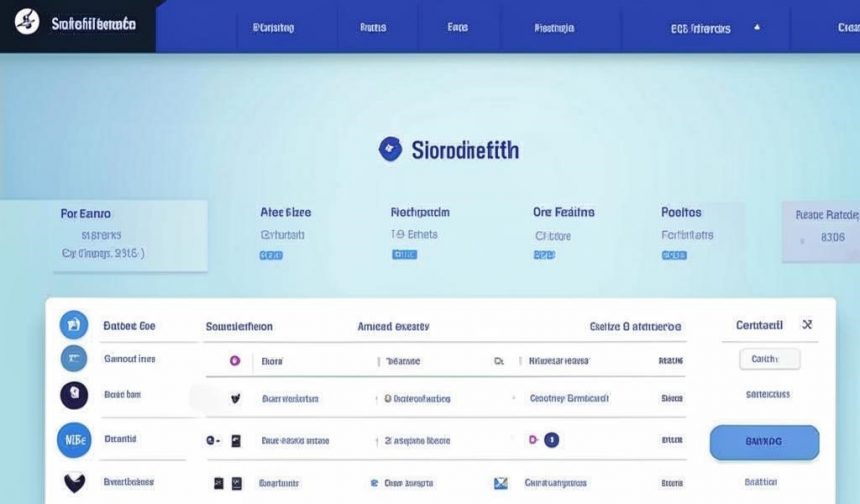
SolidityBench, запущенный IQ, стал первым рейтингом, оценивающим возможности больших языковых моделей (LLM) в генерации кода Solidity. Представленный на Hugging Face, он включает два инновационных бенчмарка: NaïveJudge и HumanEval for Solidity, предназначенных для оценки и ранжирования эффективности моделей ИИ в генерации кода смарт-контрактов.
Разработанный BrainDAO в рамках набора IQ Code, SolidityBench служит для улучшения собственных LLM EVMind и сравнения их с универсальными и созданными сообществом моделями. IQ Code стремится предоставлять модели ИИ, предназначенные для генерации и проверки кода смарт-контрактов, удовлетворяя растущую потребность в безопасных и эффективных приложениях на блокчейне.
Оценка моделей ИИ с использованием NaïveJudge
Согласно IQ, NaïveJudge предлагает новый подход, поручая LLM реализовать смарт-контракты на основе подробных спецификаций, полученных из проверенных контрактов OpenZeppelin. Эти контракты являются золотым стандартом правильности и эффективности.
Сгенерированный код оценивается по сравнению с эталонной реализацией по таким критериям, как функциональная полнота, соблюдение лучших практик Solidity и стандартов безопасности, а также эффективность оптимизации. Процесс оценки использует расширенные LLM, включая различные версии GPT-4 и Claude 3.5 Sonnet от OpenAI, в качестве беспристрастных рецензентов кода.
Они оценивают код по строгим критериям, включая реализацию всех основных функций, обработку крайних случаев, управление ошибками, правильное использование синтаксиса, а также общую структуру и удобочитаемость кода. Оптимизационные соображения, такие как эффективность использования газа и управление хранилищем, также оцениваются.
Оценка моделей ИИ с использованием HumanEval
По словам IQ, HumanEval for Solidity адаптирует оригинальный бенчмарк HumanEval от OpenAI с Python на Solidity, охватывая 25 задач различной сложности. Каждая задача включает соответствующие тесты, совместимые с Hardhat, популярной средой разработки Ethereum, что облегчает точную компиляцию и тестирование сгенерированного кода.
Метрики оценки, pass@1 и pass@3, измеряют успех модели при первых попытках и нескольких пробах, давая представление как о точности, так и о возможностях решения проблем.
Сравнение лучших моделей ИИ для разработки смарт-контрактов Solidity
Результаты бенчмаркинга показали, что модель GPT-4o от OpenAI достигла наивысшего общего балла 80,05, с баллом NaïveJudge 72,18 и показателями прохождения HumanEval for Solidity 80% при проходе@1 и 92% при проходе@3.
Интересно, что более новые модели рассуждения, такие как o1-preview и o1-mini от OpenAI, уступили первое место, набрав 77,61 и 75,08 соответственно. Модели от Anthropic и XAI, включая Claude 3.5 Sonnet и grok-2, продемонстрировали конкурентоспособные характеристики с общим баллом около 74.
Цели использования моделей ИИ в разработке смарт-контрактов
Вводя эти бенчмарки, SolidityBench стремится продвигать разработку смарт-контрактов с помощью ИИ. Это поощряет создание более сложных и надежных моделей ИИ и одновременно предоставляет разработчикам и исследователям ценную информацию о текущих возможностях и ограничениях ИИ в разработке Solidity.
Набор инструментов для бенчмаркинга направлен на продвижение LLM EVMind от IQ Code, а также устанавливает новые стандарты для разработки смарт-контрактов с использованием ИИ в экосистеме блокчейнов. Инициатива надеется удовлетворить критические потребности отрасли, где спрос на безопасные и эффективные смарт-контракты продолжает расти.
Приглашение к участию в SolidityBench
Разработчики, исследователи и энтузиасты ИИ приглашаются к изучению и участию в SolidityBench, который направлен на непрерывное улучшение моделей ИИ, продвижение передового опыта и развитие децентрализованных приложений. Посетите рейтинг SolidityBench на Hugging Face, чтобы узнать больше и начать бенчмаркинг моделей генерации Solidity.
Пульс Новости 8.57 из 10
- Значимость новости: 8/10 – Новая разработка в сфере генерации смарт-контрактов может потенциально автоматизировать сложный процесс разработки и повысить безопасность и эффективность децентрализованных приложений.
- Инновационная ценность новости: 9/10 – Внедрение бенчмарков NaïveJudge и HumanEval для Solidity в SolidityBench представляет собой инновационный подход к оценке моделей генерации кода.
- Потенциальное влияние новости на рынок: 8/10 – Улучшенные модели генерации смарт-контрактов могут снизить барьеры для входа для разработчиков блокчейна и привести к более широкому внедрению децентрализованных приложений.
- Релевантность новости: 10/10 – Новость напрямую связана с криптовалютным рынком и разработкой смарт-контрактов на Solidity.
- Актуальность новости: 10/10 – Новость недавно опубликована (21 октября 2024 года) и содержит самую новую информацию о развитии ИИ-моделей для генерации Solidity.
- Достоверность новости: 8/10 – Новость опубликована на авторитетном криптовалютном новостном сайте CryptoSlate и ссылается на источник (IQ) в отрасли.
- Общий тон новости: 7/10 – Тон новости позитивный и описывает преимущества и потенциал новой разработки.











